1️⃣ So sánh và đánh giá giữa Doc2Vec và PhoBERT
Cả hai mô hình Doc2Vec và PhoBERT đều là những phương pháp mạnh mẽ trong học biểu diễn văn bản, nhưng chúng có những đặc điểm khác nhau trong cách tiếp cận và ứng dụng:
Bảng so sánh Doc2Vec và PhoBERT
| Tiêu chí |
Doc2Vec |
PhoBERT |
| Cách tiếp cận |
Học biểu diễn văn bản dựa trên phân tích ngữ cảnh trong tập dữ liệu |
Dựa trên mô hình Transformer, tận dụng cơ chế tự chú ý (self-attention) |
| Mức độ biểu diễn |
Biểu diễn đoạn văn bản dưới dạng vector cố định, không nhạy với ngữ cảnh rộng |
Biểu diễn động, có thể thay đổi tùy vào ngữ cảnh của từ/câu trong đoạn văn |
| Khả năng nắm bắt ngữ nghĩa |
Hạn chế, không thể hiểu rõ nghĩa của từ dựa trên vị trí xuất hiện |
Hiểu rõ ngữ cảnh và mối quan hệ giữa các từ trong câu |
| Hiệu suất trên tiếng Việt |
Khá tốt, nhưng bị hạn chế bởi dữ liệu huấn luyện |
Rất tốt, được huấn luyện chuyên biệt cho tiếng Việt |
| Ứng dụng |
Phù hợp cho phân loại văn bản, truy vấn tài liệu |
Phù hợp cho nhiều tác vụ NLP như phân loại, tóm tắt, nhận diện thực thể |
Dựa trên bảng so sánh trên, nhóm thấy PhoBERT là mô hình phù hợp hơn cho bài toán khai thác thông tin trong tiếng Việt vì:
● Hiểu ngữ cảnh tốt hơn: Nhờ cơ chế tự chú ý, PhoBERT có thể nắm bắt mối quan hệ giữa các từ và câu trong văn bản, giúp nâng cao hiệu suất tìm kiếm và truy vấn thông tin.
● Tối ưu hóa cho tiếng Việt: Được huấn luyện trên tập dữ liệu tiếng Việt lớn, PhoBERT có lợi thế hơn so với Doc2Vec trong việc xử lý ngôn ngữ tự nhiên.
● Tính linh hoạt cao: Có thể áp dụng vào nhiều bài toán khác nhau trong khai thác thông tin, bao gồm tìm kiếm tài liệu, phân loại văn bản, và tóm tắt thông tin.
Vì vậy, trong phạm vi bài tiểu luận này, PhoBERT được lựa chọn làm mô hình chính để triển khai hệ thống thử nghiệm và đánh giá hiệu suất trong bài toán khai thác thông tin.
2️⃣ Chuẩn bị dữ liệu
✔️ Thu thập dữ liệu văn bản tiếng Việt từ VnExpress
Trong phần này, nhóm tiến hành thu thập dữ liệu văn bản từ trang tin tức VnExpress, một trong những nguồn tin uy tín và phong phú tại Việt Nam. Dữ liệu thu thập sẽ được sử dụng để huấn luyện và đánh giá hiệu suất của mô hình học biểu diễn văn bản PhoBERT.
✔️ Phương pháp thu thập dữ liệu
Dữ liệu được thu thập bằng cách xây dựng một web crawler sử dụng thư viện requests và BeautifulSoup để trích xuất nội dung từ các bài báo thuộc các chuyên mục khác nhau
✔️ Quy trình crawl dữ liệu
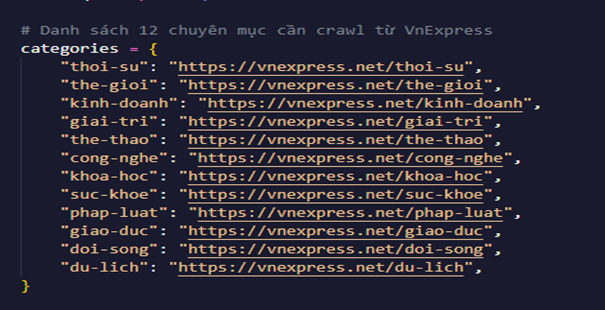
✔️ Xác định các chuyên mục cần thu thập dữ liệu
➖ Danh sách URL của các chuyên mục trên VnExpress được định nghĩa trong tập tin crawl_vnexpress.py.
➖ Mỗi chuyên mục sẽ được quét 3 trang đầu tiên để lấy danh sách các bài viết.
✔️ Lấy danh sách bài viết từ mỗi chuyên mục
➖ Crawler gửi request đến URL chuyên mục và phân tích HTML để lấy danh sách đường dẫn các bài báo.
➖ Đảm bảo chỉ thu thập các đường dẫn hợp lệ, tránh các liên kết không liên quan.
➖ Mở từng bài viết, lấy tiêu đề và nội dung từ các thẻ HTML phù hợp (<h1> cho tiêu đề, <p> cho nội dung).
➖ Kết hợp các đoạn văn bản để tạo thành một tệp văn bản chứa nội dung bài báo.
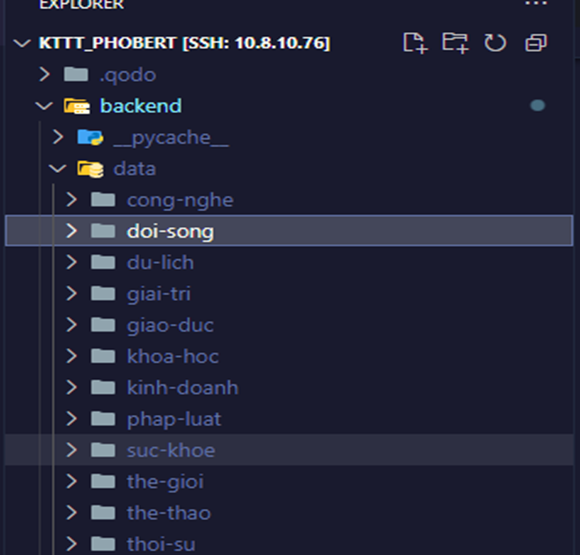
✔️ Lưu trữ dữ liệu
➖ Dữ liệu được lưu theo chuyên mục, mỗi bài báo được lưu dưới dạng một tệp .txt.
➖ Tên tệp được chuẩn hóa để tránh ký tự đặc biệt và đảm bảo không bị trùng lặp.
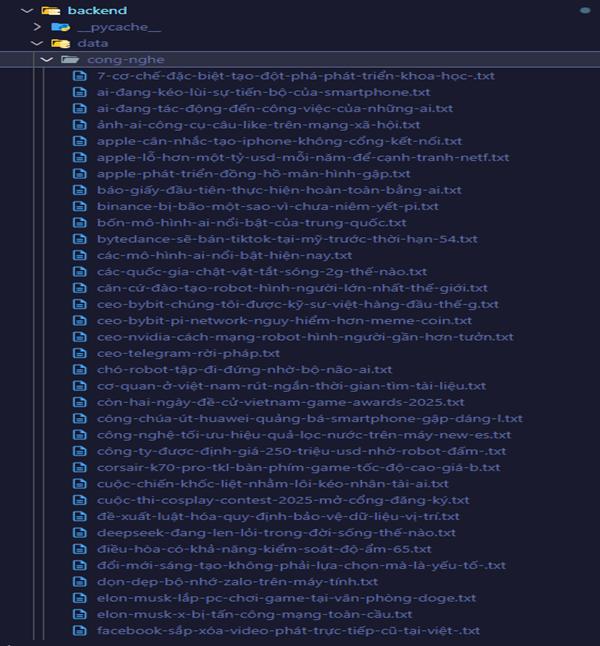
Sau khi thực hiện quá trình này, chúng tôi thu thập được một lượng lớn bài báo từ VnExpress, giúp tạo tập dữ liệu huấn luyện cho các mô hình học biểu diễn văn bản. Dữ liệu thu thập được sử dụng để đánh giá hiệu suất của PhoBERT trong bài toán khai thác thông tin.
3️⃣ Chuyển đổi dữ liệu văn bản sang vector
Sau khi thu thập dữ liệu văn bản tiếng Việt từ VnExpress, bước tiếp theo là chuyển đổi các bài viết này thành dạng vector số để phục vụ cho các bài toán khai thác thông tin. Trong bài tiểu luận này, chúng tôi sử dụng mô hình PhoBERT để học biểu diễn văn bản.
✔️ Quy trình chuyển đổi văn bản sang vector
✔️ Tải mô hình PhoBERT và tokenizer
▪️ PhoBERT là một biến thể của BERT được huấn luyện đặc biệt cho tiếng Việt.
▪️ Mô hình này có khả năng chuyển đổi văn bản thành một chuỗi vector số có ý nghĩa ngữ nghĩa.
✔️ Đọc và tiền xử lý dữ liệu
▪️ Các bài báo đã thu thập được lưu dưới dạng tệp .txt trong các thư mục theo từng chủ đề.
▪️ Chương trình duyệt qua các thư mục, đọc nội dung của từng bài viết và lưu vào danh sách để xử lý.
✔️ Mã hóa văn bản thành vector sử dụng PhoBERT
▪️ Sử dụng tokenizer để chuyển đổi văn bản thành dạng token phù hợp với PhoBERT.
▪️ Đầu vào sau khi được mã hóa sẽ được đưa vào mô hình PhoBERT để trích xuất đặc trưng (embedding).
▪️ Vector biểu diễn của văn bản được tính bằng cách lấy trung bình trên tất cả các token trong câu.
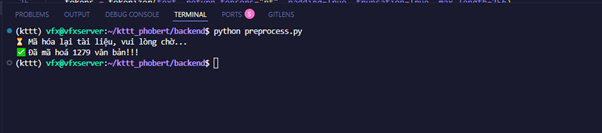
✔️ Lưu trữ kết quả
▪️ Sau khi mã hóa toàn bộ văn bản thành vector, kết quả được lưu vào tệp.npy để phục vụ cho các bước tiếp theo, bao gồm tìm kiếm và truy hồi thông tin.
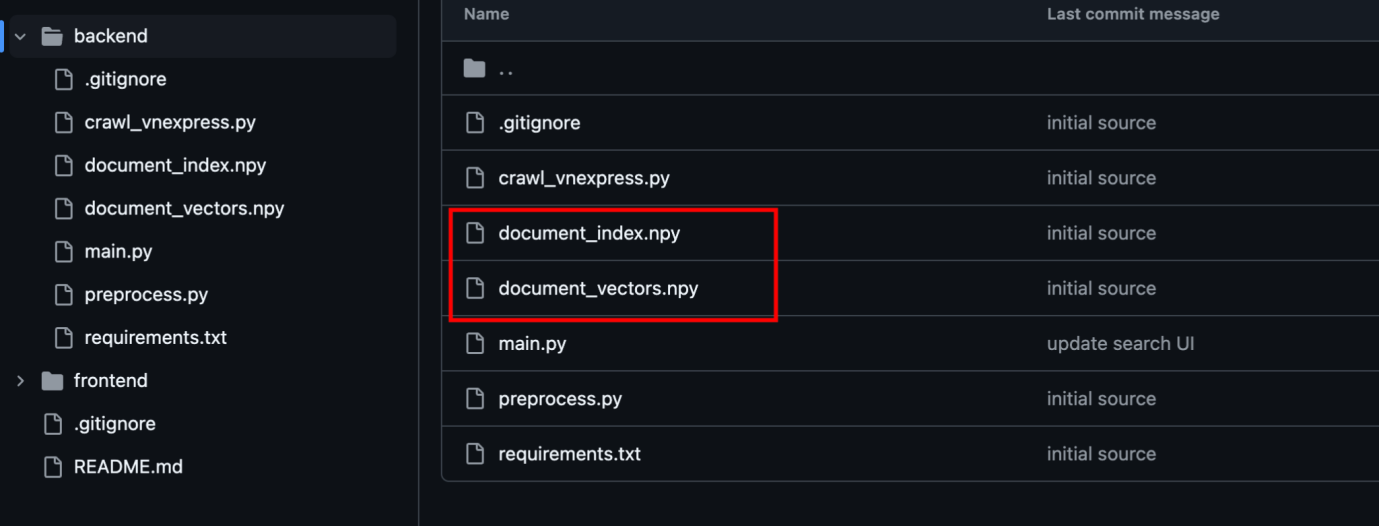
Sau khi dữ liệu văn bản đã được thu thập và chuyển đổi sang dạng vector bằng PhoBERT, bước tiếp theo là xây dựng một hệ thống truy vấn để tìm kiếm các tài liệu liên quan dựa trên độ tương đồng ngữ nghĩa.
✔️ Cách thức hoạt động
✔️ Nạp mô hình PhoBERT: API sử dụng mô hình PhoBERT (vinai/phobert-base) để mã hóa từ khóa tìm kiếm thành vector.
▪️ Nạp tập dữ liệu vector hóa
▪️ Tải danh sách vector văn bản từ file document_vectors.npy.
▪️ Tải danh sách thông tin tài liệu từ document_index.npy.
✔️ Xử lý truy vấn
▪️ Người dùng nhập từ khóa tìm kiếm.
▪️ Từ khóa này được chuyển thành vector bằng PhoBERT.
▪️ Hệ thống tính toán độ tương đồng giữa vector truy vấn và các vector tài liệu đã lưu bằng cosine similarity.
▪️ Sắp xếp tài liệu theo độ tương đồng giảm dần và trả về kết quả.
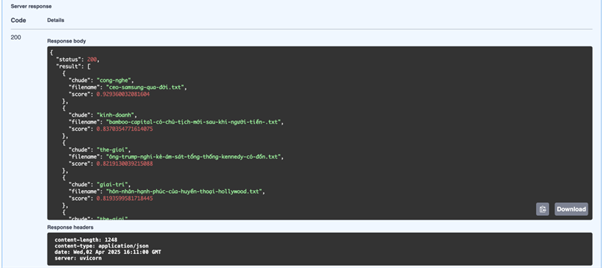
✔️ Trả về kết quả
▪️ Kết quả trả về là danh sách các tài liệu phù hợp với truy vấn, bao gồm:
▪️ Chủ đề (chude).
▪️ Tên tệp tài liệu (filename).
▪️ Điểm số độ tương đồng (score).
[1] Le, Q., & Mikolov, T., "Distributed representations of sentences and documents," in ICML, 2014.
[2] Nguyen, D. Q., & Nguyen, A. T., "Nguyen, D. Q., & Nguyen, A. T.," in
Findings of the Association for Computational Linguistics: EMNLP, 2020.
https://github.com/VinAIResearch/PhoBERT
https://huggingface.co/vinai/phobert-base
Khánh Tùng - Khoa CNTT, Robot & Trí tuệ nhân tạo.
 Hội thảo Quốc gia lần thứ XXII – Một số vấn đề chọn lọc của công nghệ thông tin và truyền thông
Hội thảo Quốc gia lần thứ XXII – Một số vấn đề chọn lọc của công nghệ thông tin và truyền thông
 Thông báo đăng ký thực hiện đồ án tốt nghiệp đợt 01 năm 2024 cho sinh viên Đại học chính quy ngành Công nghệ thông tin
Thông báo đăng ký thực hiện đồ án tốt nghiệp đợt 01 năm 2024 cho sinh viên Đại học chính quy ngành Công nghệ thông tin
 THAM QUAN NHÀ MÁY PANASONIC ELECTRIC WORKS MỞ RA "TẦM NHÌN MỚI" CHO "HỢP TÁC MỚI"
THAM QUAN NHÀ MÁY PANASONIC ELECTRIC WORKS MỞ RA "TẦM NHÌN MỚI" CHO "HỢP TÁC MỚI"
 THÔNG BÁO: Thực hiện đồ án tốt nghiệp đợt 2 năm 2023
THÔNG BÁO: Thực hiện đồ án tốt nghiệp đợt 2 năm 2023
 Lễ Bảo vệ đồ án tốt nghiệp tại Khoa FIRA: Khẳng định sự hấp dẫn của ngành Công nghệ Thông tin
Lễ Bảo vệ đồ án tốt nghiệp tại Khoa FIRA: Khẳng định sự hấp dẫn của ngành Công nghệ Thông tin
 "Company Tour" cho sinh viên - Nâng cao nhận thức cho sinh viên tại FIRA.BDU
"Company Tour" cho sinh viên - Nâng cao nhận thức cho sinh viên tại FIRA.BDU





 Zalo
Zalo
 Messenger
Messenger
 Youtube
Youtube
 Maps
Maps


